Les agents IA s’imposent progressivement comme une évolution naturelle des assistants classiques. On les retrouve aujourd’hui dans de nombreux cas d’usage : automatisation de tâches, génération de contenu, support client ou encore assistance produit.
Dans le domaine de la documentation technique et du support, leur promesse est particulièrement forte. De plus en plus d’équipes produit les déploient pour répondre aux utilisateurs, automatiser certaines actions et réduire la charge opérationnelle.
Sur le papier, le fonctionnement semble simple : un agent capable de comprendre une demande, d’exploiter la documentation et de fournir une réponse pertinente, sans intervention humaine.
Dans la réalité, les résultats sont souvent décevants.
Les réponses manquent de précision, certaines informations sont absentes et, dans de nombreux cas, l’agent ne parvient pas à résoudre le problème. Les utilisateurs finissent alors par ouvrir un ticket… comme avant.
Face à ces limites, le réflexe est presque toujours le même : changer de modèle, tester une nouvelle solution ou retravailler les prompts.
Mais ce n’est généralement pas là que se situe le problème.
Un agent IA ne comprend pas votre produit par défaut. Il dépend entièrement des informations qu’il peut exploiter. Et dans la plupart des cas, cette base de connaissance repose sur un élément largement sous-estimé : la documentation produit.
Si cette documentation est incomplète, mal structurée ou déconnectée des usages réels, l’agent ne peut pas produire de réponses fiables — quel que soit le modèle utilisé.
Autrement dit, améliorer un agent IA ne consiste pas seulement à optimiser la technologie. Il s’agit surtout de lui fournir une connaissance produit exploitable.
Dans cet article, nous allons voir pourquoi les agents IA échouent souvent en pratique, en quoi la documentation produit est déterminante dans leur performance, et ce qu’il faut réellement améliorer pour les rendre utiles au quotidien.
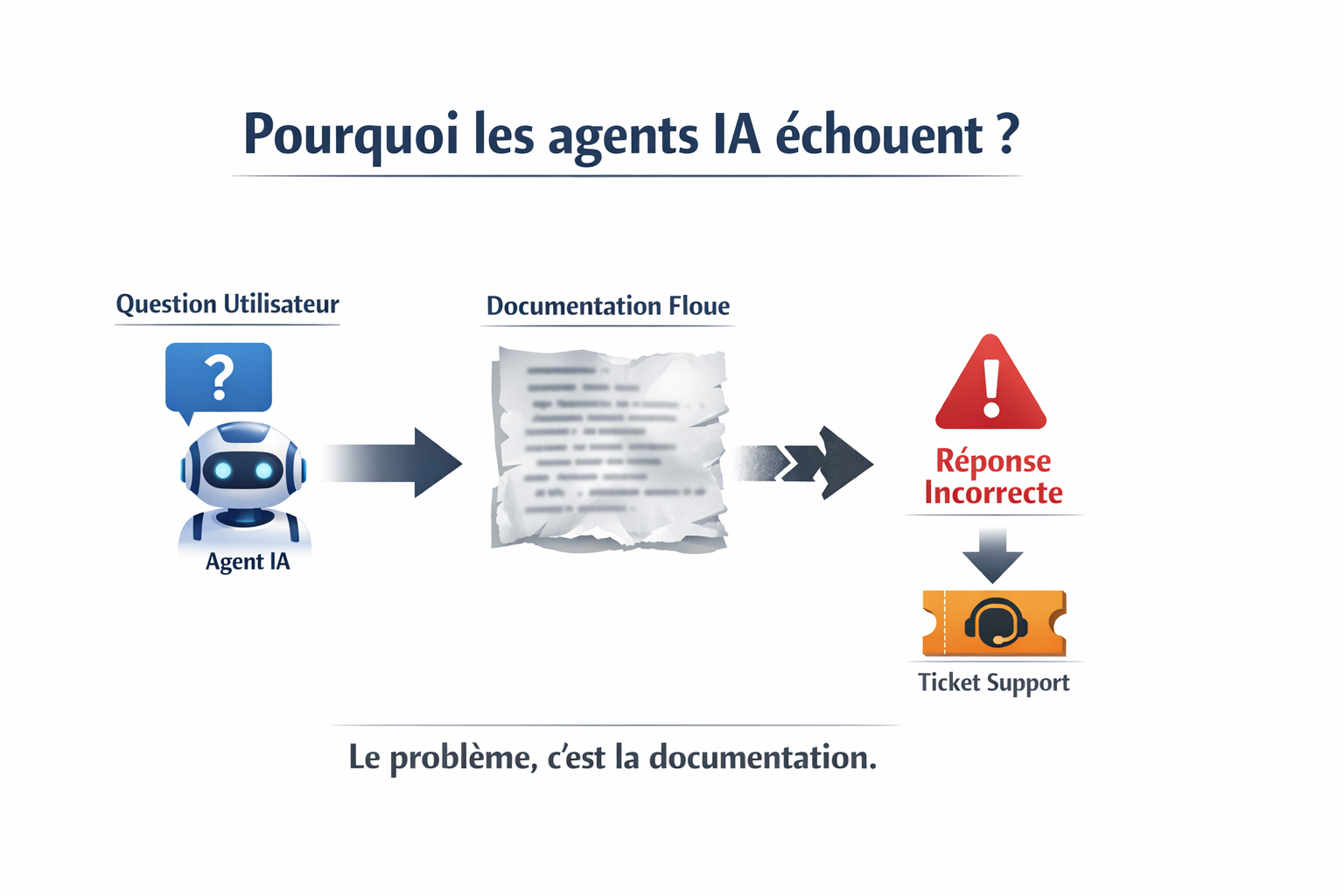
Pourquoi les agents IA semblent prometteurs… mais déçoivent en pratique#
Sur le papier, les agents IA promettent de transformer en profondeur le support et la documentation produit.
Ils sont censés :
- répondre instantanément aux utilisateurs ;
- automatiser une grande partie des demandes ;
- réduire la charge des équipes support ;
- et améliorer l’autonomie à grande échelle.
Dans les démonstrations, le résultat est souvent convaincant. Les réponses sont rapides, bien formulées et donnent l’impression d’une compréhension solide du produit.
Mais une fois déployés en conditions réelles, l’écart devient évident.
Ce que les entreprises attendent des agents IA#
Les équipes produit et support attendent des agents IA qu’ils soient capables de :
- comprendre des questions variées ;
- s’adapter au contexte utilisateur ;
- fournir des réponses fiables ;
- et remplacer une partie du support humain.
Autrement dit, elles attendent un système réellement autonome, capable de s’appuyer sur la documentation existante pour répondre correctement.
Ce que les utilisateurs constatent réellement#
Dans la pratique, l’expérience est souvent plus mitigée.
Les utilisateurs constatent que :
- certaines réponses restent trop vagues ;
- des informations essentielles sont absentes ;
- certaines instructions ne permettent pas d’aller au bout de l’action ;
- et, dans certains cas, les réponses sont tout simplement incorrectes.
Résultat : l’agent est utilisé… mais ne remplace pas réellement le support.
Pourquoi le problème ne vient pas seulement du modèle#
Face à ces limites, le réflexe est presque toujours le même :
- changer de modèle ;
- ajuster les prompts ;
- tester une autre solution.
Ces optimisations peuvent améliorer la forme des réponses, mais rarement leur pertinence réelle.
Le problème n’est donc pas uniquement technologique.
👉 Il est structurel.
Pour comprendre pourquoi les agents IA échouent en pratique, il faut regarder non pas le modèle… mais la base de connaissance sur laquelle il s’appuie.
Le vrai problème : un agent IA ne comprend pas votre produit par défaut#
Contrairement à un humain, un agent IA ne possède aucune connaissance intrinsèque de votre produit.
Il ne « comprend » pas vos fonctionnalités, vos parcours ou vos cas d’usage.
Il s’appuie uniquement sur les informations auxquelles il a accès pour formuler une réponse.
Autrement dit, la performance d’un agent IA dépend directement de la qualité de sa base de connaissance.
Dans la majorité des cas, cette base repose sur un élément clé : la documentation produit.
Un agent IA ne « connaît » que ce qu’on lui donne#
Un agent IA fonctionne toujours selon le même principe :
- il reçoit une question ;
- il recherche des informations dans une base de contenu ;
- il génère une réponse à partir de ces éléments.
S’il ne trouve pas la bonne information, il ne peut pas la deviner.
S’il trouve une information ambiguë ou incomplète, il produira une réponse incertaine.
Contrairement à un humain, il ne peut pas combler les manques ni interpréter les zones floues.
La documentation produit devient sa base de connaissance#
Dans un système basé sur du RAG (Retrieval-Augmented Generation), la documentation devient la source principale de vérité.
C’est elle qui permet à l’agent IA de :
- comprendre les fonctionnalités ;
- expliquer les parcours ;
- guider les actions utilisateurs.
Si cette documentation est :
- mal structurée ;
- incomplète ;
- ou déconnectée des usages réels ;
alors l’agent IA ne dispose tout simplement pas d’une connaissance exploitable pour répondre correctement.
Pourquoi une mauvaise connaissance produit génère de mauvaises réponses#
Un point clé souvent sous-estimé : un agent IA ne corrige pas les défauts d’une documentation.
Il les amplifie.
- Une information floue → une réponse floue
- Une information incomplète → une réponse incomplète
- Une information incorrecte → une réponse incorrecte
Plus le modèle est performant, plus ces défauts deviennent visibles.
Ce constat change complètement la manière d’aborder le sujet.
La question n’est plus seulement :
« Comment améliorer un agent IA ? »
Mais plutôt :
« Quelle qualité de connaissance produit lui donne-t-on pour répondre correctement ? »
Pourquoi votre documentation produit bloque vos agents IA#
Si les agents IA échouent souvent, ce n’est pas seulement parce que la technologie a ses limites.
Dans de nombreux cas, le vrai problème vient de la documentation produit sur laquelle ils s’appuient. Une documentation peut sembler correcte pour un lecteur humain, tout en restant difficilement exploitable par un système automatisé.
Autrement dit, la difficulté ne vient pas uniquement du contenu lui-même, mais aussi de sa structure, de sa cohérence et de son alignement avec les usages réels.
Une documentation pensée pour la lecture, pas pour l’exploitation par un agent#
La plupart des documentations produit sont conçues pour être lues par des humains.
Elles reposent souvent sur :
- des explications narratives ;
- des implicites ;
- des raccourcis de formulation ;
- et des connaissances supposées.
Un humain peut interpréter ces éléments, faire des liens et combler certaines zones floues.
Un agent IA, lui, dépend beaucoup plus directement de ce qui est formulé, structuré et accessible dans les contenus.
Des contenus fragmentés, incohérents ou incomplets#
Dans de nombreuses bases de connaissance, l’information est dispersée :
- plusieurs pages traitent du même sujet ;
- certaines se contredisent ;
- d’autres sont incomplètes ;
- et certaines ne sont plus à jour.
Pour un utilisateur, cela crée de la confusion.
Pour un agent IA, cela crée de l’incertitude au moment de récupérer et d’interpréter l’information.
Résultat : les réponses deviennent instables, approximatives ou incohérentes.
Un décalage entre la documentation et les questions réelles des utilisateurs#
Un problème fréquent vient du fait que la documentation est organisée selon la logique du produit, et non selon les questions réellement posées.
Les contenus décrivent des fonctionnalités, alors que les utilisateurs expriment surtout :
- des problèmes ;
- des objectifs ;
- des blocages ;
- ou des actions à réaliser.
Ce décalage rend plus difficile :
- la recherche d’information ;
- la correspondance entre une question et un contenu ;
- et donc la génération d’une réponse pertinente.
L’agent ne trouve pas toujours la bonne information, même lorsqu’elle existe.
Des informations introuvables au moment où l’agent en a besoin#
Enfin, il arrive que la documentation contienne bien la réponse… sans la rendre exploitable au bon moment.
Cela peut être lié à :
- un mauvais découpage des contenus ;
- un manque de structure ;
- une hiérarchie peu claire ;
- ou une organisation mal adaptée à la recherche.
Dans ce cas, l’information existe, mais elle reste difficile à récupérer et à mobiliser dans le contexte précis de la question posée.
Ce type de documentation peut encore fonctionner pour un lecteur humain motivé. En revanche, il limite fortement la capacité d’un agent IA à produire des réponses fiables.
La suite est logique : lorsqu’un agent s’appuie sur une base de connaissance de mauvaise qualité, les conséquences se voient immédiatement dans ses réponses.
Ce qui se passe quand un agent IA s’appuie sur une mauvaise documentation#
Une fois le problème identifié, ses conséquences deviennent rapidement visibles.
Un agent IA ne « compense » pas une documentation imparfaite. Il s’appuie directement sur elle pour produire ses réponses. Lorsque la base de connaissance est mal structurée, incomplète ou désalignée avec le produit, cela se reflète immédiatement dans l’expérience utilisateur.
Ces effets ne sont pas théoriques. Ils apparaissent concrètement dans les réponses générées, dans les parcours utilisateurs… et dans la perception globale de l’agent.
Des réponses approximatives ou trop génériques#
Lorsque l’information est floue ou mal structurée, l’agent IA produit des réponses qui le sont aussi.
Cela se traduit souvent par :
- des explications vagues ;
- des réponses trop générales ;
- des formulations correctes… mais peu exploitables.
L’agent « parle bien », mais n’aide pas réellement à résoudre le problème.
Ce type de réponse donne une illusion de qualité, tout en laissant l’utilisateur dans l’incertitude.
Des erreurs ou des hallucinations#
Lorsque la documentation est incomplète ou incohérente, l’agent peut produire des réponses incorrectes.
Il peut :
- combiner des informations incompatibles ;
- interpréter des contenus ambigus ;
- ou générer des réponses plausibles mais fausses.
Ces erreurs ne viennent pas uniquement du modèle, mais du manque de fiabilité des sources.
Plus la base de connaissance est fragile, plus le risque d’hallucination augmente.
Des parcours utilisateurs bloqués#
Même lorsque la réponse semble pertinente, elle ne permet pas toujours d’aller au bout de l’action.
L’utilisateur peut :
- comprendre une partie du problème ;
- suivre certaines étapes ;
- mais se retrouver bloqué à un moment clé.
Ce blocage intervient souvent lorsque :
- des étapes sont manquantes ;
- des prérequis ne sont pas mentionnés ;
- ou des cas spécifiques ne sont pas couverts.
Dans ces situations, l’agent devient une étape intermédiaire… avant le support.
Une perte de confiance dans l’agent IA#
Le problème le plus critique n’est pas technique. Il est lié à la perception.
Après plusieurs réponses approximatives ou inutiles, les utilisateurs perdent confiance.
Ils :
- vérifient systématiquement les réponses ;
- hésitent à suivre les instructions ;
- ou contournent complètement l’agent.
À partir de ce moment, même une bonne réponse perd de sa valeur.
L’agent n’est plus perçu comme un outil fiable, mais comme une étape supplémentaire dans le parcours.
Ces effets montrent une réalité simple : la performance d’un agent IA dépend moins de sa capacité à générer du texte que de la qualité des informations qu’il peut exploiter.
C’est pourquoi améliorer la technologie seule ne suffit pas.
La question devient alors : pourquoi changer de modèle ou optimiser les prompts ne permet-il pas réellement de corriger ces problèmes ?
Pourquoi changer de modèle ne suffit pas à corriger le problème des agents IA#
Face à des résultats décevants, le réflexe est presque toujours le même : remettre en cause le modèle utilisé.
Faut-il passer sur un modèle plus récent ?
Tester une autre solution ?
Optimiser davantage les prompts ?
Ces pistes peuvent améliorer certains aspects, mais elles ne traitent pas le problème de fond.
Un agent IA reste dépendant des informations qu’il peut exploiter. Si la base de connaissance est défaillante, aucun modèle ne peut produire des réponses fiables de manière durable.
Des modèles puissants restent dépendants du contexte fourni#
Même les modèles les plus avancés ne « connaissent » pas votre produit.
Ils s’appuient uniquement sur :
- le contexte fourni (RAG, documents, mémoire) ;
- les instructions données (prompts) ;
- et les informations accessibles au moment de la requête.
Autrement dit, leur performance est directement limitée par la qualité de ce contexte.
Un meilleur modèle peut :
- mieux formuler une réponse ;
- mieux structurer l’information ;
- mieux gérer les nuances ;
mais il ne peut pas inventer une information absente ni corriger une documentation incorrecte.
Le RAG améliore l’accès à l’information, mais ne corrige pas une mauvaise base#
Le Retrieval-Augmented Generation (RAG) permet d’améliorer l’accès à la documentation en sélectionnant les contenus les plus pertinents pour répondre à une question.
C’est un levier puissant… mais souvent mal compris.
Le RAG ne fait que :
- retrouver de l’information ;
- la transmettre au modèle ;
- et l’intégrer dans la réponse.
Si les contenus récupérés sont :
- incomplets ;
- incohérents ;
- ou mal structurés ;
alors le problème reste entier.
Le RAG améliore l’accès à l’information, mais ne garantit pas sa qualité.
Pourquoi la qualité des sources compte plus que le choix du modèle#
Dans la pratique, la différence entre deux modèles est souvent moins déterminante que la qualité des sources utilisées.
Une documentation claire, structurée et alignée avec les usages permet à un agent de produire des réponses fiables… même avec un modèle intermédiaire.
À l’inverse, une documentation floue ou incohérente limite fortement les performances, même avec les meilleurs modèles disponibles.
C’est un changement de perspective important :
- optimiser le modèle améliore la forme des réponses ;
- améliorer la documentation transforme leur pertinence.
Au final, le véritable levier de performance ne se situe pas uniquement dans la technologie, mais dans la qualité de la connaissance produit.
La question devient alors : qu’est-ce qu’une documentation réellement exploitable par un agent IA ?
Ce qu’il faut vraiment améliorer pour rendre un agent IA utile#
Une fois le problème identifié, la question n’est plus « quel modèle utiliser ? », mais « qu’est-ce qu’il faut réellement améliorer pour qu’un agent IA soit utile au quotidien ? ».
La réponse est rarement technique.
Dans la majorité des cas, les gains les plus importants ne viennent pas d’un changement de modèle, mais d’une amélioration de la documentation produit — à condition de la rendre réellement exploitable par un agent IA.
Structurer une documentation exploitable par une IA#
Une documentation pensée pour un humain n’est pas forcément adaptée à une machine.
Pour être exploitable par un agent IA, elle doit être :
- découpée de manière logique ;
- cohérente d’une page à l’autre ;
- explicite dans ses étapes et ses formulations ;
- et suffisamment précise pour être interprétée sans ambiguïté.
L’objectif n’est pas de simplifier à l’extrême, mais de rendre l’information directement utilisable, sans effort d’interprétation.
Une bonne structure ne sert pas uniquement à améliorer la lecture humaine.
Elle conditionne directement la qualité des réponses générées par l’agent IA.
Aligner la documentation avec les questions réelles des utilisateurs#
Un agent IA répond à des questions, pas à des fonctionnalités.
Si la documentation est organisée selon la logique interne du produit, il devient difficile pour l’agent de faire le lien entre une question utilisateur et le bon contenu.
Améliorer cet alignement consiste à :
- utiliser le vocabulaire réel des utilisateurs ;
- structurer les contenus autour des problèmes concrets ;
- couvrir les questions réellement posées.
Plus cet alignement est fort, plus l’agent est capable d’identifier rapidement l’information pertinente.
Corriger les contenus ambigus, incomplets ou obsolètes#
Les contenus problématiques sont souvent déjà identifiés :
- explications floues ;
- étapes manquantes ;
- incohérences entre plusieurs pages ;
- décalage avec le produit réel.
Pour un humain, ces défauts créent de la friction.
Pour un agent IA, ils deviennent des erreurs.
Corriger ces points permet d’améliorer directement :
- la précision des réponses ;
- la capacité à aller au bout d’une action ;
- la fiabilité globale de l’agent.
Rendre l’information accessible au bon moment du parcours#
Une information peut être correcte… sans être utile si elle n’est pas accessible au bon moment.
Pour un agent IA, cela dépend notamment :
- du découpage des contenus ;
- de leur structuration ;
- de leur capacité à être retrouvés rapidement dans un contexte donné.
L’enjeu n’est donc pas seulement de documenter, mais de rendre l’information immédiatement exploitable au moment où la question est posée.
Améliorer ces éléments transforme directement la performance d’un agent IA.
Mais pour aller plus loin, il ne suffit pas d’optimiser la documentation.
Il faut aussi comprendre comment elle est réellement utilisée dans les interactions avec les utilisateurs.
Le lien clé : usage réel, documentation produit et performance de l’agent IA#
Améliorer la documentation produit est une première étape.
Mais pour comprendre pourquoi un agent IA fonctionne — ou échoue — il faut aller plus loin.
Ce qui fait réellement la différence, ce n’est pas uniquement ce qui est documenté.
C’est la manière dont cette documentation est utilisée en pratique.
Autrement dit, la performance d’un agent IA dépend directement de l’usage réel des contenus :
- quelles questions sont posées ;
- quels contenus sont consultés ;
- et où les utilisateurs rencontrent des blocages.
C’est ce lien entre usage, documentation produit et réponses générées qui permet d’identifier les vrais leviers d’amélioration.
Pourquoi les questions utilisateurs sont une donnée stratégique#
Un agent IA répond à des questions.
Ces questions constituent donc l’entrée principale du système.
Elles reflètent :
- les besoins réels des utilisateurs ;
- leur vocabulaire ;
- leurs incompréhensions ;
- et les situations concrètes dans lesquelles ils bloquent.
Sans cette donnée, la documentation reste théorique et déconnectée du terrain.
À l’inverse, analyser les questions permet de :
- identifier les sujets réellement critiques ;
- détecter les zones mal couvertes ;
- et aligner les contenus avec les usages réels.
Plus la documentation est proche des questions utilisateurs, plus l’agent est capable de produire des réponses pertinentes.
Comprendre quels contenus sont réellement utilisés#
Toutes les pages d’une documentation n’ont pas le même impact.
Certains contenus jouent un rôle central :
- ils sont fréquemment consultés ;
- ils interviennent dans des parcours critiques ;
- ils influencent directement la capacité de l’agent IA à répondre.
D’autres restent secondaires, voire inutilisés.
Comprendre quels contenus sont réellement utilisés permet de :
- concentrer les efforts là où l’impact est réel ;
- éviter d’améliorer des pages peu utiles ;
- renforcer les points clés de la base de connaissance.
Sans cette visibilité, les équipes améliorent la documentation de manière diffuse, sans effet mesurable.
Identifier les points de friction qui dégradent les réponses de l’agent#
Le signal le plus important ne vient pas des contenus eux-mêmes, mais de ce qui se passe après leur consultation.
Un contenu problématique est souvent :
- consulté… mais suivi d’un échec ;
- utilisé… sans permettre d’aller au bout de l’action ;
- présent… mais insuffisant dans le contexte réel.
Ces points de friction se traduisent directement dans les réponses de l’agent :
- réponses incomplètes ;
- instructions bloquantes ;
- incapacité à résoudre le problème.
Identifier ces zones permet d’agir là où l’impact est maximal : non pas en produisant plus de contenu, mais en corrigeant ce qui empêche réellement l’agent d’être utile.
Comprendre ce lien entre usage réel, documentation produit et performance de l’agent change complètement l’approche.
La documentation n’est plus seulement un support d’information.
Elle devient un composant central du système IA.
La question devient alors : pourquoi la documentation est-elle en train de devenir un enjeu stratégique pour tous les systèmes basés sur l’IA ?
Pourquoi la documentation devient un enjeu stratégique pour les systèmes IA#
Pendant longtemps, la documentation produit a été perçue comme un simple support : un ensemble de guides destinés à aider les utilisateurs à comprendre un outil.
Avec l’arrivée des agents IA, ce rôle change profondément.
La documentation ne sert plus uniquement à expliquer.
Elle devient une source de connaissance directement utilisée par des systèmes automatisés pour répondre, guider et agir.
Autrement dit, elle n’est plus seulement un contenu.
Elle devient une infrastructure critique dans la performance des systèmes IA.
D’une documentation statique à une documentation pilotée#
Dans la plupart des organisations, la documentation reste encore gérée comme un contenu statique :
- on rédige des guides ;
- on les publie ;
- on les met à jour ponctuellement.
Ce modèle fonctionne tant que la documentation est utilisée uniquement par des humains.
Mais dès qu’un agent IA s’appuie dessus, ses limites apparaissent rapidement.
Une documentation statique ne permet pas de :
- comprendre quels contenus sont réellement utilisés ;
- identifier les zones qui posent problème ;
- ni corriger rapidement les points de friction.
Pour être réellement exploitable dans un système IA, la documentation doit évoluer vers un modèle piloté :
- basé sur les usages réels ;
- ajusté en continu ;
- et orienté vers l’efficacité plutôt que la complétude.
Le rôle des analytics dans la performance des agents IA#
Ce passage à une documentation pilotée repose sur un élément clé : l’analyse des usages.
Les agents IA génèrent une quantité importante de signaux :
- les questions posées ;
- les contenus consultés ;
- les réponses produites ;
- les échecs et les escalades vers le support.
Ces données permettent de comprendre concrètement :
- où la documentation produit fonctionne ;
- où elle échoue ;
- et quels contenus doivent être améliorés en priorité.
Sans cette analyse, l’amélioration reste intuitive.
Avec elle, la documentation devient mesurable, pilotable et optimisable.
C’est ce lien entre documentation analytics et performance des agents IA qui permet de passer d’un système « fonctionnel » à un système réellement utile.
Pourquoi la qualité documentaire devient un sujet produit, support et IA#
Ce changement de rôle a une conséquence directe : la documentation ne peut plus être gérée de manière isolée.
Elle devient un sujet transverse, au croisement de plusieurs équipes :
- le produit, qui définit les fonctionnalités et les parcours ;
- le support, qui observe les problèmes réels ;
- et les équipes IA, qui exploitent cette connaissance pour répondre automatiquement.
Une documentation de faible qualité n’impacte plus seulement l’expérience utilisateur.
Elle dégrade directement :
- la performance des agents IA ;
- la fiabilité des réponses ;
- et le volume de tickets support.
À l’inverse, une documentation claire, structurée et alignée avec les usages devient un avantage compétitif.
Elle permet :
- de rendre les agents réellement utiles ;
- de réduire les frictions dans les parcours ;
- et d’améliorer l’autonomie des utilisateurs à grande échelle.
Ce basculement est fondamental.
Les agents IA ne rendent pas la documentation optionnelle.
Ils la rendent stratégique.
La question n’est donc plus « faut-il améliorer la documentation ? »
Mais : comment la transformer en une base de connaissance réellement exploitable par des systèmes IA ?
Conclusion#
Les agents IA donnent l’impression de pouvoir transformer le support et la documentation à eux seuls.
En réalité, leur performance repose sur un facteur beaucoup plus fondamental : la qualité de la connaissance produit qu’ils exploitent.
Une documentation incomplète, difficile à trouver ou déconnectée des usages réels limite directement leur capacité à répondre. À l’inverse, une documentation claire, structurée et alignée avec les questions des utilisateurs devient un levier puissant pour améliorer les réponses, fluidifier les parcours et réduire les frictions.
Autrement dit, le problème n’est pas seulement technologique.
Il est documentaire.
Les équipes qui obtiennent des résultats concrets avec les agents IA ne se contentent pas d’optimiser leurs modèles. Elles travaillent leur documentation comme une base de connaissance stratégique, pilotée par l’usage réel et améliorée en continu.
Dans ce contexte, comprendre comment la documentation est utilisée — quelles questions sont posées, quels contenus sont consultés, où les utilisateurs bloquent — devient essentiel pour rendre un agent réellement utile.
C’est précisément ce que permet une approche comme la documentation analytics, en reliant les usages, les contenus et les points de friction.
Dans cette logique, Doklear aide les équipes produit, support et documentation à comprendre l’usage réel de leur documentation, à identifier les contenus qui limitent la performance des agents IA et à concentrer leurs efforts là où ils ont le plus d’impact.
Un agent IA n’est jamais meilleur que la connaissance qu’on lui donne.
Et aujourd’hui, cette connaissance repose plus que jamais sur la documentation produit.